

How Can We Help?
UCloud switchboard error reports
The Toolbox – PBX signals section is very useful for diagnosing problems, most of the time, related to your own connectivity or to some badly configured terminal or UI, other times related to VoIP operators.
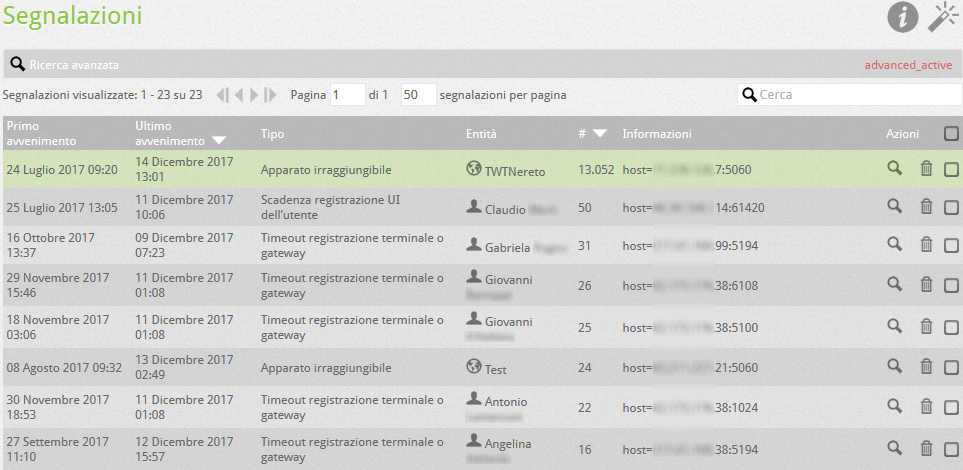
This section shows the anomalous events relating to the various entities (users, gateways, UI) of the switchboard. Each new event has a start date (first event): if the same event occurs again for the same entity, a progressive counter (Number of events) is updated showing the date / time of the last event (Last event). In this way, events can be counted starting from the first to the last occurrence. If, therefore, in a relatively short time range, the number of events is particularly high, the problem can manifest itself in a macroscopic way for users of the switchboard.
The monitored events are as follows:
-
- Terminal or gateway registration timeout: registration timeout of the indicated entity.
- Device authentication failed: wrong credentials for the client entity indicated (physical gateway, and users)
- Failed authentication to the carrier: incorrect credentials for the server entity indicated (voip operators)
- Unreachable apparatus: unreachable entity. For example, the VoIP account configured in the PBX has banned the UCloud server IP
- Unexpected IP / Source Port change: entity port change during the current session
- Device expire time too short: recording time too short for the indicated entity (minimum accepted 60 seconds)
- Too many unencrypted requests from the device: too many retransmissions from the client entity indicated
- Too many unencrypted requests from the server: too many server retransmissions to the indicated entity
- No SSE connection with the user’s UI: unable to establish an SSE connection for the indicated user’s UI
- Excessive loss of packets from the gateway: excessive loss of specks causes the lack of audio in the conversation that affected the indicated entity (typically a gateway)
- User UI registration deadline: connection timeout of the indicated UI
- Device authentication challenge deadline: the terminal did not respond in time to the PBX challenge for authentication
| Following interventions carried out on your network or on a terminal, it is possible to reset the statistics by deleting the single event, by clicking on the corresponding trash can icon, or, by acting on the magic wand at the top, deleting entire groups of reports as shown on the side |  |
Typology of problems and reports
While not being able to list all the possible problems (described in detail on this page), we will give some general indications on the meaning of these reports.
Failed device authentication events clearly indicate an error in the login credentials.
Terminal or gateway registration timeout events indicate login disconnections of the indicated entity that has no longer appeared at the PBX. Too many unencrypted requests from the device can be associated with events, which indicate that the PBX has sent too many confirmations to the REGISTER requests of the terminal. This indicates that the PBX confirmations do not arrive at the terminal which, not receiving them, persists in always sending the same signal which is then thrown away with the connection timeout result. These phenomena may be related to NAT configurations (of routers or firewalls) whose sessions are too short compared to the registration time of the indicated entity. In principle, it is absolutely necessary that the duration of the NAT sessions is equal to or greater than the minimum of the recording times used by phones and gateways (our provisionig sets these times to 60 seconds).
Problems of this kind can lead to the inability to make and receive calls with the classic feeling that the switchboard has “blocked”: the truth is different: in fact, restarting the router / firewall often returns to normal. Therefore, it is necessary to investigate the efficiency of the active equipment.
These timeout events can also be a symptom of “connectivity holes”, which can be triggered by physical problems on the company’s connectivity, or by problems with some active equipment such as routers and firewalls. In this case it is necessary to investigate the quality of the connection together with your provider.
Events of an unexpected IP / Source Port change indicate that the router from which the terminals exit has changed the source port for the indicated entity: this is normally not a problem since the PBXs follow this port changes: however, a frequent change of port may indicate a bad NAT configuration again with too short sessions.
Events of type no SSE connection with the user’s UI, indicate the impossibility for the UI to make a connection with the server: typically the responsibility lies with the firewall that must guarantee TCP navigation on ports 3542 and the HTTP port indicated in the information of your company.
Events of excessive packet loss from the gateway, indicates the lack of audio in one or both directions, linked to the router’s NAT settings or to a routing problem with the operator.
When to be alarmed
Events of any kind can always be present in this section, but this does not necessarily indicate a problem recognized by users. In fact, Internet browsing itself could have numerous problems, but the user is not aware of them until the situation worsens to such an extent that the connection is “slow”. The reports of VOIspeed are instead very punctual, to the point that their mere presence could lead to think of a big problem. In reality, it is first of all necessary to receive user reports and then observe the number of events of each report: there is no minimum daily number of events above which one should think of a chronic and serious problem. In fact, this limit depends on too many factors such as the number of active users, the number of calls made, the degree of use of connectivity. What is certain is that if out of 10 events with “low” numbers, a couple with a higher order of magnitude stand out, we should consider first those, which could be isolated cases and then the others. If all 10 events have a similar and high number (let’s say at least over ten per day), you can worry: for this reason, every time an internal network maintenance is carried out, it would be worth noting these signals and then clearing them to get an idea of the results obtained.